



LetsMap: Unsupervised Representation Learning for Semantic BEV Mapping
Nikhil Gosala, Kürsat Petek, B Ravi Kiran, Senthil Yogamani, Paulo L.J. Drews-Jr, Wolfram Burgard, Abhinav Valada
European Conference on Computer Vision (ECCV) 2024
Nikhil Gosala, Kürsat Petek, B Ravi Kiran, Senthil Yogamani, Paulo L.J. Drews-Jr, Wolfram Burgard, Abhinav Valada
European Conference on Computer Vision (ECCV) 2024

Existing approaches used to generate instantaneous Bird's-Eye-View (BEV) segmentation maps from frontal view (FV) images rely on the presence of large annotated BEV datasets as they are trained in a fully-supervised manner. However, BEV ground truth annotation relies on the presence of HD maps, annotated 3D point clouds, and/or 3D bounding boxes which are extremely resource-intensive and difficult to obtain. Some approaches circumvent this limitation by leveraging data from simulation environments - but these approaches are often victim to the large domain gap between simulated and real-world images - which results in their reduced performance on real-world data.
There is thus a significant need to allow for the generation of instantaneous BEV maps without relying on large amounts of annotated data in BEV. In this work, we address the aforementioned challenges by proposing LetsMap, the first unsupervised representation learning framework for generating semantic BEV maps from monocular FV images in a label-efficient manner. Find out more about our state-of-the-art unsupervised framework in the approach section!
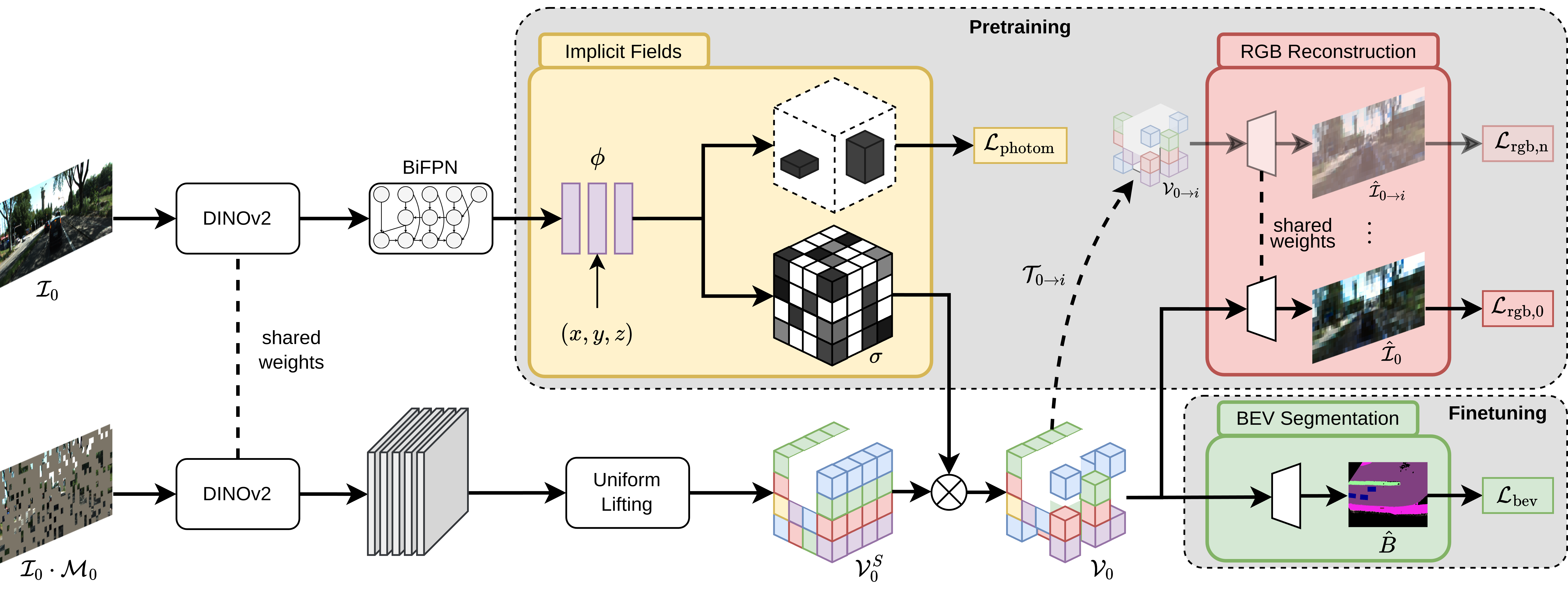
The goal of our LetsMap framework is to output BEV semantic map predictions from monocular FV images in a label-efficient manner. The key idea of our approach is to leverage sequences of multi-camera FV images to learn the two core sub-tasks of semantic BEV mapping, i.e., scene geometry modeling and scene representation learning, using two disjoint neural pathways following a label-free paradigm. After two core tasks are learnt, the model is adapted to a given downstream task in a label-efficient manner. We achieve this desired behavior by splitting the training protocol into sequential FV pretraining and BEV finetuning stages. The FV pretraining stage learns to explicitly model the scene geometry by enforcing scene consistency over multiple views using the photometric loss. Parallelly, the scene representation is also learnt by reconstructing a masked input image over multiple time steps using the reconstruction loss. Upon culmination of the pretraining phase, the finetuning phase adapts the network to the task of semantic BEV mapping using the cross-entropy loss on the tiny fraction of available BEV labels.
Our architecture comprises five main components, namely:
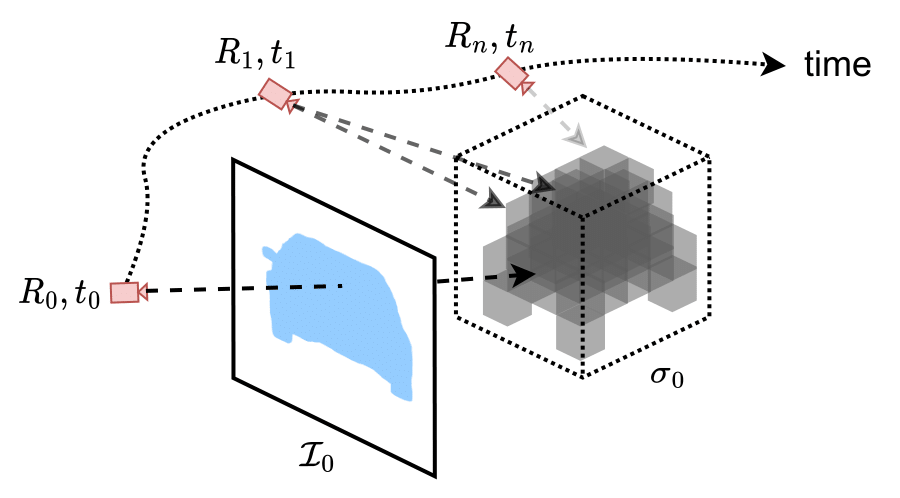
The goal of the geometric pathway is to explicitly model scene geometry in a label-free manner using only the spatio-temporal images obtained from cameras onboard an autonomous vehicle. Explicit scene geometry modeling allows the network to reason about occlusions and disocclusions in the scene, thus improving the quality of predictions in the downstream task. To this end, we design the task of scene geometry learning using an implicit field formulation wherein the main goal is to estimate the volumetric density of the scene in the camera coordinate system given a monocular FV image. We multiply the estimated volumetric density with the uniformly-lifted semantic features to generate the geometrically consistent semantic features.

The semantic pathway aims to facilitate the learning of holistic feature representations for various scene elements in a label-free manner. This rich pretrained representation enables efficient adaptation to semantic classes during finetuning. To this end, we learn the representations of scene elements by masking out random patches in the input image and then forcing the network to generate pixel-wise predictions for each of the masked patches. Moreover, we also exploit the temporal consistency of static elements in the scene by reconstructing the RGB images at future timesteps \(t_1, t_2, ..., t_n\) using the masked RGB input at timestep \(t_0\). This novel formulation of temporal masked autoencoding (T-MAE) allows our network to learn spatially- and semantically consistent features which improve its occlusion reasoning ability and accordingly its performance on semantic BEV mapping.
Nikhil Gosala,
Kürsat Petek,
B Ravi Kiran,
Senthil Yogamani,
Paulo L.J. Drews-Jr,
Wolfram Burgard,
Abhinav Valada
"LetsMap: Unsupervised Representation Learning for Semantic BEV Mapping"
European Conference on Computer Vision (ECCV), 2024.
This work was partially funded by Qualcomm Technologies Inc. and a hardware grant from NVIDIA.






